
The purpose of this post is to give a firm a high-level strategy as to how one could conduct a language processing project. According to wikipedia, natural language processing is 'A subfield of linguistics, computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human languages, in particular how to program computers to process and analyze large amounts of natural language data.' For now, we will first have to create a strategy around language processing. Subsequent posts will show some tutorials on how to conduct language processing in python on some real live data. For now, we are just giving you a pre-cursor on how to get started.
Steps:
1) Select which model to use - For the purpose of this post, you could use the language processing model called 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.' The BERT model was created by Google in 2018, as a neural network (A neural network is a network or circuit of neurons, or in a modern sense, an artificial neural network, composed of artificial neurons or nodes) and is used for pre-training data. One needs to pre-train data for the model to have sufficient information to analyze subsequent data points to make decisions.
What we want to point out is that when our firm conducts any type of data science projects, we choose the best model for you, based off of every single model available. Our findings have been that most individuals will just pick a random model to implement on a client side, but have not looked at other alternatives. Today, you may not be obtaining the best model for your business problem.
How does the BERT model work?
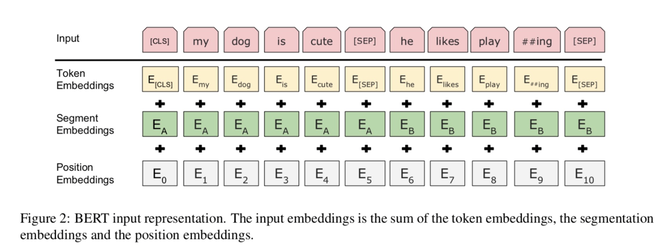
1) All text that is entered into the model must be lowercase (as you can see in the figure below [if you are on mobile it is above] in red)
2) Tokenization must occur (Tokenization is a way of separating a piece of text into smaller units called
tokens. Here, tokens can be either words, characters, or subwords) - please look at the yellow box below [if you are on mobile it is above]
3) Next, text segmentation must occur (segmentation is the process of dividing written text into meaningful units, such as words, sentences, or topics. The term applies both to mental processes used by humans when reading text, and to artificial processes implemented in computers, which are the subject of natural language processing.
4) The position embedding's must be applied (positional embedding's are used to encode order dependencies into the input representation. However, this input representation only involves static order dependencies based on discrete numerical information, that is, are independent of word content.)
5) In part II of this tutorial, we will select a programming language to conduct natural language processing with. We prefer python, which is a general purpose interpreted programming language.
6) We need to define what we are looking for. For the purpose of this tutorial, we will focus on negative news, so that we can determine whether or not a new piece of news is negative
7) Lastly, each tokenized text source will bounce off the corpus (https://www.english-corpora.org/wiki/), and generally will be given a computational output of the model as to how close the text is to the corpus to categorize the text. Typically, the Wikipedia corpus is used because the Wikipedia corpus contains the full text of Wikipedia, and it contains 1.9 billion words in more than 4.4 million articles. The corpus can also be a sub-set of data such as all negative news. We need to classify the corpus in order to determine whether or not a piece of news is negative.
Stay tuned for the tutorial!
Steps:
1) Select which model to use - For the purpose of this post, you could use the language processing model called 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.' The BERT model was created by Google in 2018, as a neural network (A neural network is a network or circuit of neurons, or in a modern sense, an artificial neural network, composed of artificial neurons or nodes) and is used for pre-training data. One needs to pre-train data for the model to have sufficient information to analyze subsequent data points to make decisions.
What we want to point out is that when our firm conducts any type of data science projects, we choose the best model for you, based off of every single model available. Our findings have been that most individuals will just pick a random model to implement on a client side, but have not looked at other alternatives. Today, you may not be obtaining the best model for your business problem.
How does the BERT model work?
1) All text that is entered into the model must be lowercase (as you can see in the figure below [if you are on mobile it is above] in red)
2) Tokenization must occur (Tokenization is a way of separating a piece of text into smaller units called
tokens. Here, tokens can be either words, characters, or subwords) - please look at the yellow box below [if you are on mobile it is above]
3) Next, text segmentation must occur (segmentation is the process of dividing written text into meaningful units, such as words, sentences, or topics. The term applies both to mental processes used by humans when reading text, and to artificial processes implemented in computers, which are the subject of natural language processing.
4) The position embedding's must be applied (positional embedding's are used to encode order dependencies into the input representation. However, this input representation only involves static order dependencies based on discrete numerical information, that is, are independent of word content.)
5) In part II of this tutorial, we will select a programming language to conduct natural language processing with. We prefer python, which is a general purpose interpreted programming language.
6) We need to define what we are looking for. For the purpose of this tutorial, we will focus on negative news, so that we can determine whether or not a new piece of news is negative
7) Lastly, each tokenized text source will bounce off the corpus (https://www.english-corpora.org/wiki/), and generally will be given a computational output of the model as to how close the text is to the corpus to categorize the text. Typically, the Wikipedia corpus is used because the Wikipedia corpus contains the full text of Wikipedia, and it contains 1.9 billion words in more than 4.4 million articles. The corpus can also be a sub-set of data such as all negative news. We need to classify the corpus in order to determine whether or not a piece of news is negative.
Stay tuned for the tutorial!
 RSS Feed
RSS Feed